
Machine learning is just a function takes encoded representation of input $x$ and maps it to encoded representation of output $y$. Does the way we choose to encode the input has an impact on the model? Can we represent an image better than a grid of pixels with 3 channels for RGB? Can we represent an audio clip better than a spectrogram?
Imagine we hadn't chosen to encode images as grids of pixels, would we be using CNN today? I think this a very intriguing question to understand how much the method of encoding has impacted the algorithm. If you had a different representations, would you come up with different algorithms? Because to me, it's not at all obvious that one particular representation is particularly good or a particularly bad. Maybe there are other better ones.
Perhaps we can train a neural network to represent them better? That's key idea behind the recent, mind blowing paper SIREN; they encode an image in the weights of a single neural network. Think of overfitting an entire neural network by training it with a single image. The neural network has to learn a compact representation of just a single image. If neural network are capable of learning to differentiate between thousand of image classes in ImageNet, it surely can overfit a single image, right?
In this paper they used a very simple MLP for this but the conventional non-linear activation functions like ReLU and TanH is replaced with the periodic sine function. Because ReLus are not that great at learning representations.
They also seemed to suggest a initialization scheme in the paper but it seems similar to the default initializer in Tensorflow. Why sine is outperforming ReLU and what's so special about sine?
What is sine?
I have not bothered to understand or appreciate sine beyond the "SOH CAH TOA" until now. It is beautifully explained in detail at here, with some missing pieces. I will attempt to summarize it here.
Sine is a repeating pattern that is one dimensional. It moves up and down. Starts from 0, moves to 1 and then dives to -1, finally returns to 0. Sine is a gentle back and forth rocking pattern.
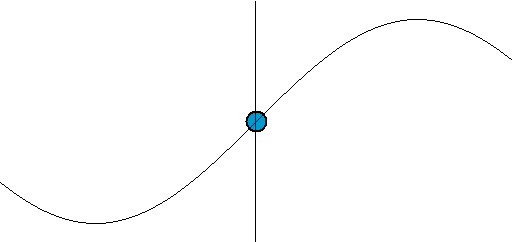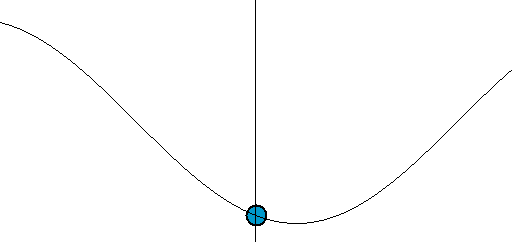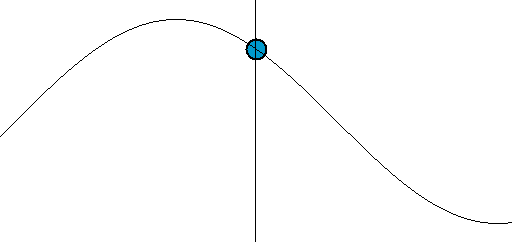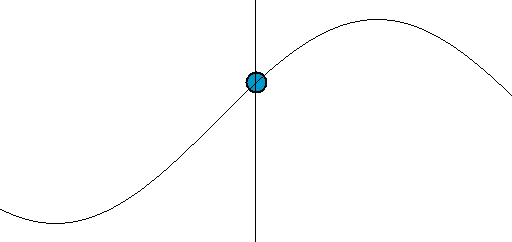
The speed of sine is non-linear, it speeds up & slows down in cycles. Let's say it takes 10 seconds for sine to move from 0 to 1. After the first 5 seconds it would have traveled 70% distance. It will take another 5 seconds to travel the remaining 30%. And going from 98% to 100%, the final 2% takes almost a full second!
How sine is difference between circles? Just like how squares are examples of lines, circles are examples of sine.
Let's define $\pi$ as the time sine takes from 0 to 1 and back to 0. Similarly, $\pi$ is the time from 0 to -1 and back to 0. $\pi$ is about returning to center or 0. So it takes 2 * $\pi$ for a full cycle.

What's special about sine?
The derivative of a sine is also a sine — as cosine is just a shifted sine. Whut?
$ \frac{d}{dx} sin(x) = cos(x) \\ \frac{d}{dx} cos(x) = - sin(x) $
If we plot the graphs, $cos(x)$ is just $sin(x)$ horizontally shifted by $\frac{\pi}{2}$
$\begin{aligned} sin(x) &= cos(x - \frac{\pi}{2}) \\ cos(x) &= sin(x + \frac{\pi}{2}) \end{aligned}$

None of other commonly used non-linear activation functions has this property. This allows us to not only represent the image itself but its derivatives too!
Another benefit is neural representations are continuous and sort of has unlimited resolution, just like reality. When we take a picture, the camera sensor is actually sampling reality discretely couple of micrometers apart from one pixel to another. Let's say if you want to know the color of an image at coordinate (x, y), you can't ask for the RGB value the between those two discrete pixels. You'd have a constraint that x and y must be an integer within the range of the image's height and width. Neural representation doesn't have this limitation and you can query what's the color of an image at (1.2, 200.5)? You can query multiple resolutions of the image with the same representation!
Alright. Let's dive into the code. The original paper was implemented in Pytorch but the following is my attempt to reproduce it in Tensorflow.
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
in_features = 2
out_features = 1
hidden_features = 256
hidden_layers = 3
outermost_linear = True
first_omega_0=30.
hidden_omega_0=30.
class Siren(keras.layers.Layer):
def __init__(self, in_features = 2, hidden_features=256, is_first=False, is_linear=False, omega_0=30.):
super(Siren, self).__init__()
self.omega_0 = omega_0
self.is_first = is_first
self.is_linear = is_linear
if is_first:
init = tf.keras.initializers.RandomUniform(minval=-1 / in_features, maxval=1 / in_features)
else:
init = tf.keras.initializers.RandomUniform(minval=-np.sqrt(6 / in_features) / omega_0, maxval=np.sqrt(6 / in_features) / omega_0)
#From https://www.tensorflow.org/guide/keras/custom_layers_and_models
self.w = self.add_weight(shape=(in_features, hidden_features), initializer=init, trainable=True)
self.b = self.add_weight(shape=(hidden_features,), initializer="zeros", trainable=True)
def call(self, inputs):
if self.is_linear:
return tf.matmul(inputs, self.w) + self.b
return tf.sin(tf.multiply(self.omega_0, tf.matmul(inputs, self.w) + self.b))That's it, the only different part is we're using the initializer as exactly referenced in the paper. Before we train the model, we need couple of helper functions (which I have not ported over to Tensorflow).
import torch
from torch import nn
from PIL import Image
import skimage
from torchvision.transforms import Resize, Compose, ToTensor, Normalize
import time
import matplotlib.pyplot as plt
def get_mgrid(sidelen, dim=2):
'''Generates a flattened grid of (x,y,...) coordinates in a range of -1 to 1.
sidelen: int
dim: int'''
tensors = tuple(dim * [torch.linspace(-1, 1, steps=sidelen)])
mgrid = torch.stack(torch.meshgrid(*tensors), dim=-1)
mgrid = mgrid.reshape(-1, dim)
return mgrid
def get_cameraman_tensor(sidelength):
img = Image.fromarray(skimage.data.camera())
transform = Compose([
Resize(sidelength),
ToTensor(),
Normalize(torch.Tensor([0.5]), torch.Tensor([0.5]))
])
img = transform(img)
return imgFinally, we can train the model and the output should be close to the input image.
BATCH_SIZE = 8192
EPOCHS = 100
sidelength = 256
img = get_cameraman_tensor(sidelength)
print(img.shape)
pixels = img.permute(1, 2, 0).view(-1, 1)
coords = get_mgrid(sidelength, 2)
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
inputs = tf.keras.Input(shape=(2,))
x = Siren(in_features=2, is_first=True)(inputs)
x = Siren(in_features=256)(x)
x = Siren(in_features=256)(x)
x = Siren(in_features=256)(x)
outputs = Siren(in_features=256, hidden_features=1, is_linear=True)(x)
model = keras.Model(inputs=inputs, outputs=outputs, name="Siren")
model.summary()
train_dataset = tf.data.Dataset.from_tensor_slices((coords, pixels))
train_dataset = train_dataset.batch(BATCH_SIZE).cache() #.shuffle(10000)
train_dataset = train_dataset.prefetch(tf.data.experimental.AUTOTUNE)
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-4)
loss = tf.keras.losses.MeanSquaredError(reduction=tf.keras.losses.Reduction.NONE)
model.compile(optimizer, loss=loss)
model.fit(train_dataset, epochs=EPOCHS, verbose=0)
result = model.predict(train_dataset)
plt.imshow(result.reshape(256,256))